




Introduction
Recommender systems are machines which recommends an object (an item, a product, a service, etc.) to a user. They are a family of algorithms which suggest items to users based on their previous interactions with the system. It's a technique which is widely used by websites like Amazon and Netflix. Indeed, more than 70% of the revenue from Amazon comes from recommendations. Recommender systems are not new. The first ones have been created in the 1960's and more than 70% of the customers from Amazon comes from its recommender system. But recommenders can also be used for other things than online shops such as for example books or videos and potentially for collaborative filtering.
Collaborative Recommender Systems encourage user contribution in an unstructured social database or knowledge sharing arena. A user reviews items, adding domain specific expert ratings to an already existing collection of data. Although not as common as collaborative filtering, collaborative recommendation finds its place where minimum amount of information about user’s taste is available. In fact, the nature of collaborative relations in recommender systems is to let users express their part of knowledge on items when there are few ways of achieving this with the latter. This paper describes a methodology for establishing a Collaborative Recommender System where no up-front classifier training and item rating is required. It has been illustrated using an example system that can be proved practical and efficient even though it resembles very closely its offline version developed many years ago.
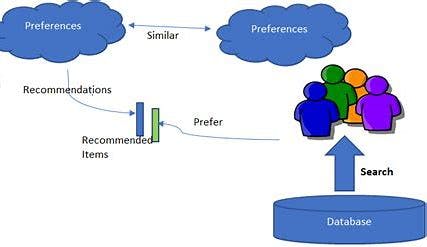
About The Dataset
The dataset is collected by Cai-Nicolas Ziegler on August / September 2004 from the Book-Crossing community. Contains 278,858 users (anonymized but with demographic information) providing 1,149,780 ratings (explicit / implicit) about 271,379 books.
The Dataset comprises 3 files:
A) Users
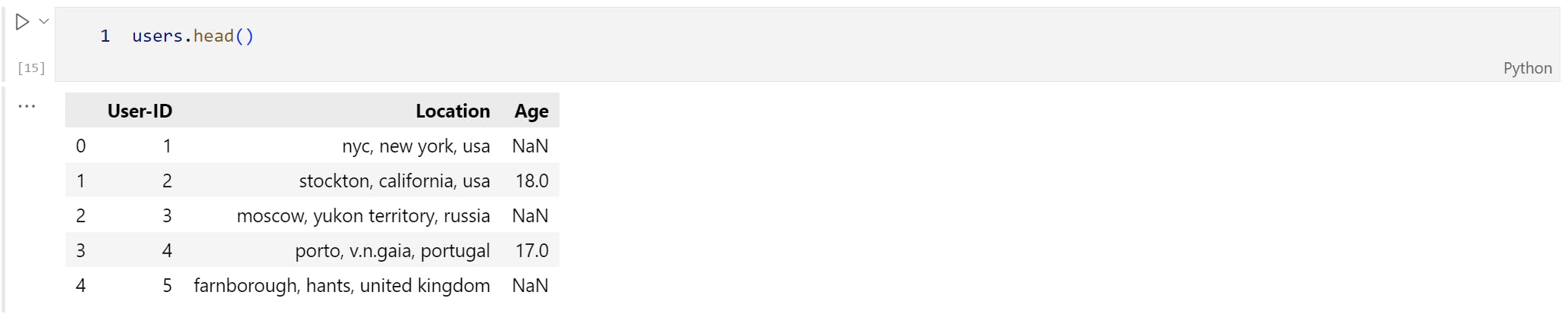
Contains the users. Note that user IDs (User-ID) have been anonymized and map to integers. Demographic data is provided (Location, Age) if available. Otherwise, these fields contain NULL values.
B) Books
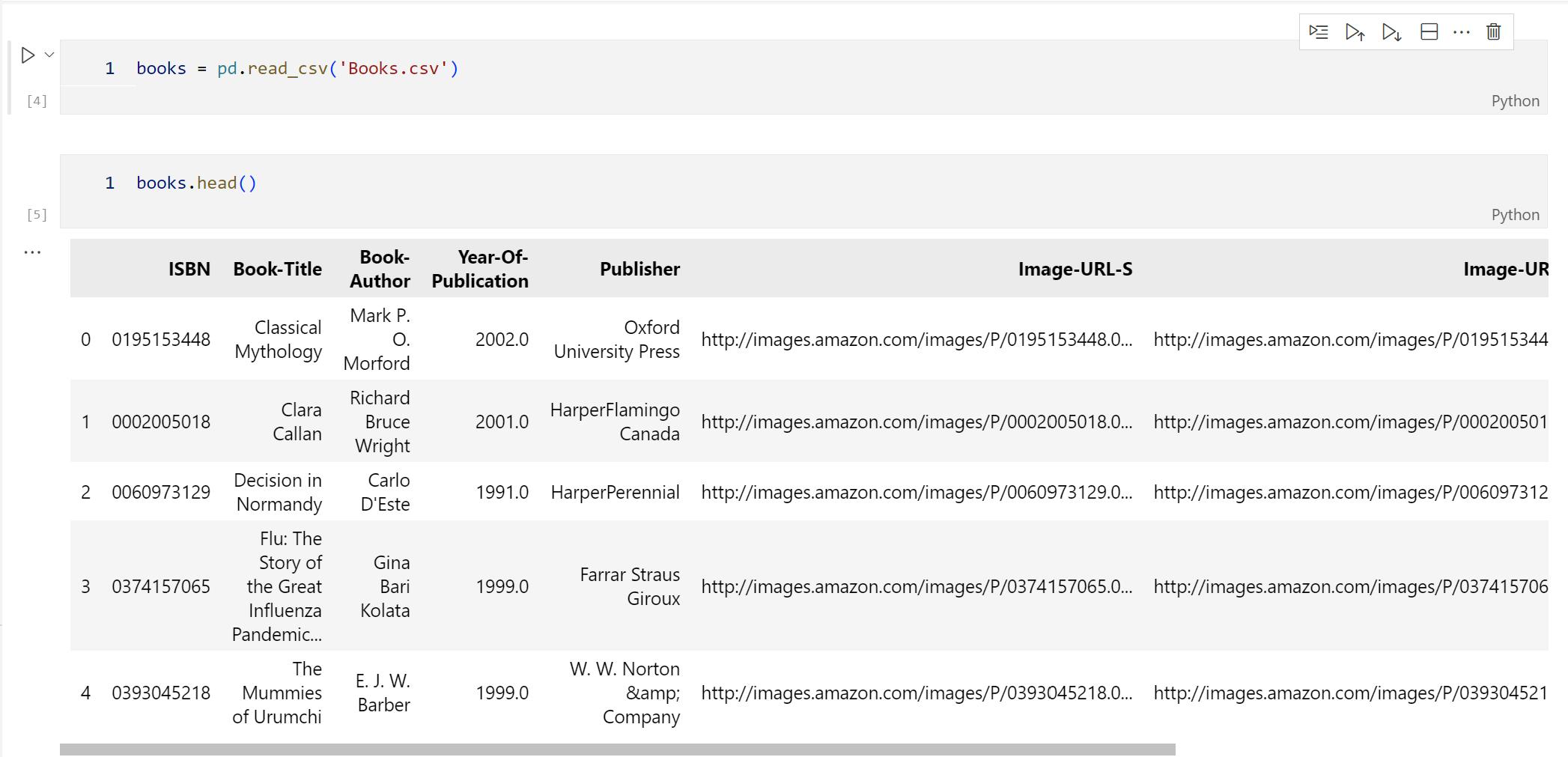
Books are identified by their respective ISBN. Invalid ISBNs have already been removed from the dataset. Moreover, some content-based information is given (Book-Title, Book-Author, Year-Of-Publication, Publisher), obtained from Amazon Web Services. Note that in case of several authors, only the first is provided. URLs linking to cover images are also given, appearing in three different flavors (Image-URL-S, Image-URL-M, Image-URL-L), i.e., small, medium, large. These URLs point to the Amazon web site.
C) Ratings
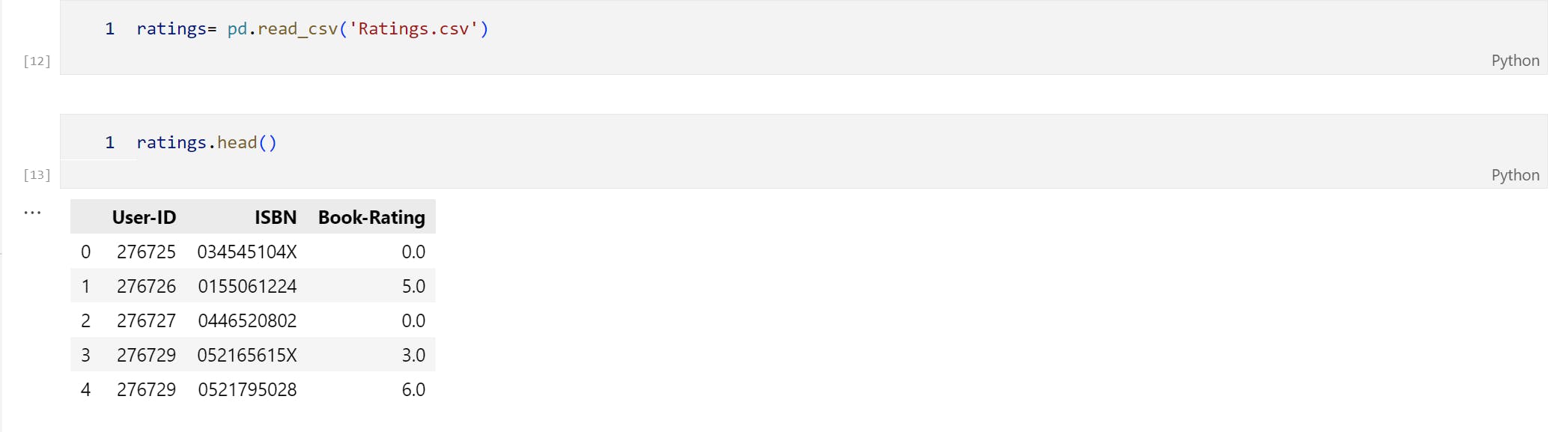
Contains the book rating information. Ratings (Book-Rating) are either explicit, expressed on a scale from 1-10 (higher values denoting higher appreciation), or implicit, expressed by 0.
Hands On Recommendation System
Importing Datasets And Liberaries
The Project was made in the Google Colab. In this stage we first we need to install necessary libraries i.e., NumPy (to work with arrays) and Pandas (for manipulating dataframes).
After importing the libraries, now it's time to load our dataset files as 'Book', 'ratings' and 'users'.
Data Preprocessing
After oberversing the book dataset, we noticed that URL columns (Image-URL-S, Image-URL-M, Image-URL-L) plays no role in the analysis. so, we removed these columns. In order to do that you can either use drop() or just simply rewrite the book variable with selected columns.
Here, I used later approach.

Problem statement
After closely observing the dataset, there is not any correlation between users and books. According to collaborative recommendation, suppose user A who reads and liked x and y books, and user B has also liked these two books and now user A has read and liked some z book which is not read by B, so we have to recommend z book to user B.
To solve this we used Matrix Factorization, which create one matrix where columns would be users and indexes would be books and value would be rating. Like a pivot table.
The Approach: As we can see from the dataset that there were users who registered the website and read one or two book. So, these types of users aren't reliable for modeling. As we have to extract knowledge from data. So, we entertain only those folks who rates at least 200 books as well as books that have at least 50 ratings on that book.
EDA
Now, let's explore the book dataset.

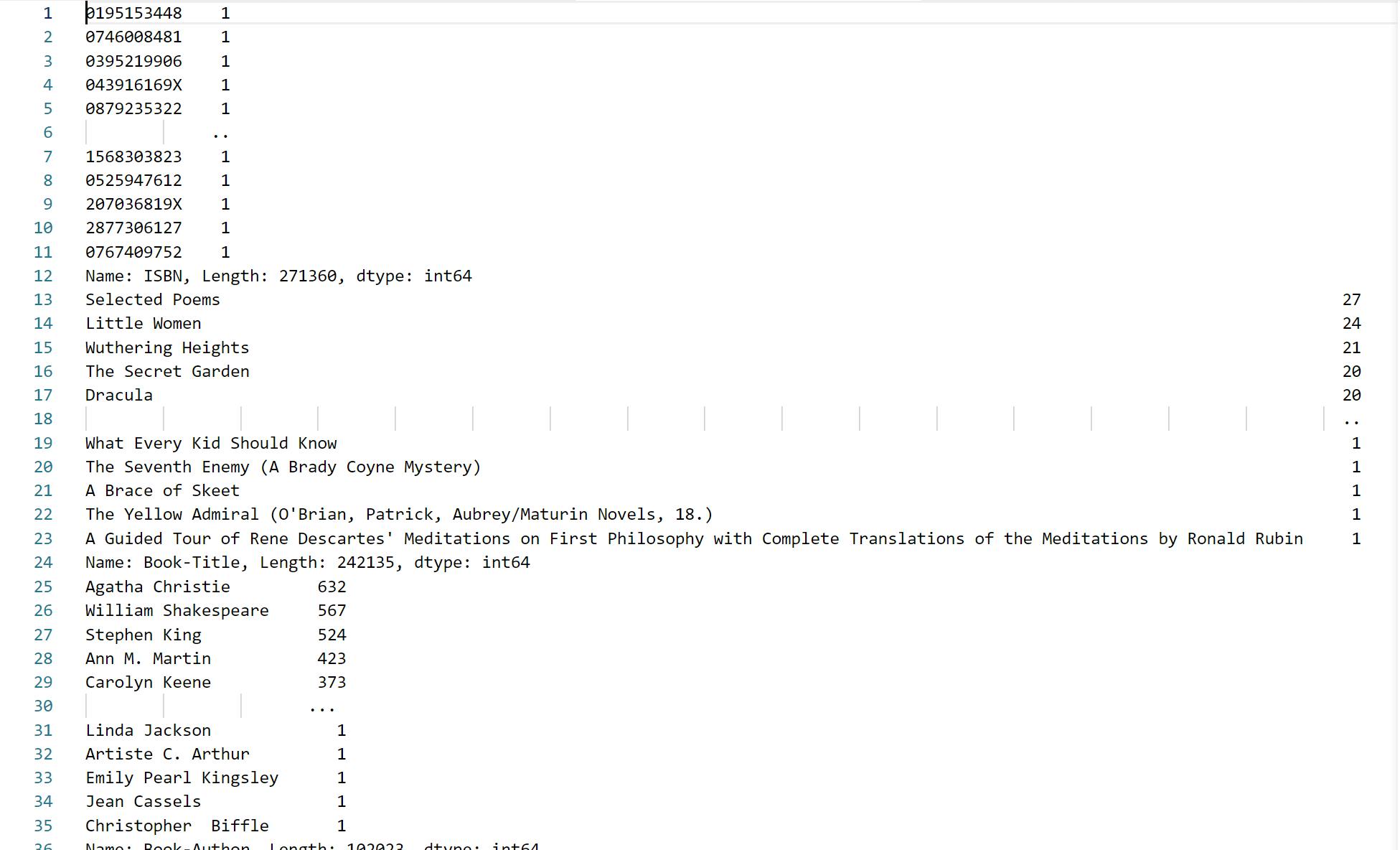
As we can see here that, Selected Poems, Little Women, Wuthering Heights, The Secret Garden and Dracula are the most popular among the readers.
Corresponding, Agatha Christie, William Shakespeare, Stephen King, Ann M. Martin, Carolyn Keene are favorite Authors of readers.
Now, let's explore the ratings dataset

As we can observe from the data that most of the people rates 0 which is fine as they are those who haven't rate those books.
Popularity Based Recommender System (Optional)
Now, merging the two datasets i.e., 'books' and 'ratings'.
Extraction of number of ratings per book by the users.
Extraction of average of ratings per book by the users.
Now, merging the above two datasets i.e., num_rating and avg_rating.
The above dataframe are the result of books according to the average user ratings. so, we are going to take top 20 from it. Now, we can assign a variable 'popular_books'

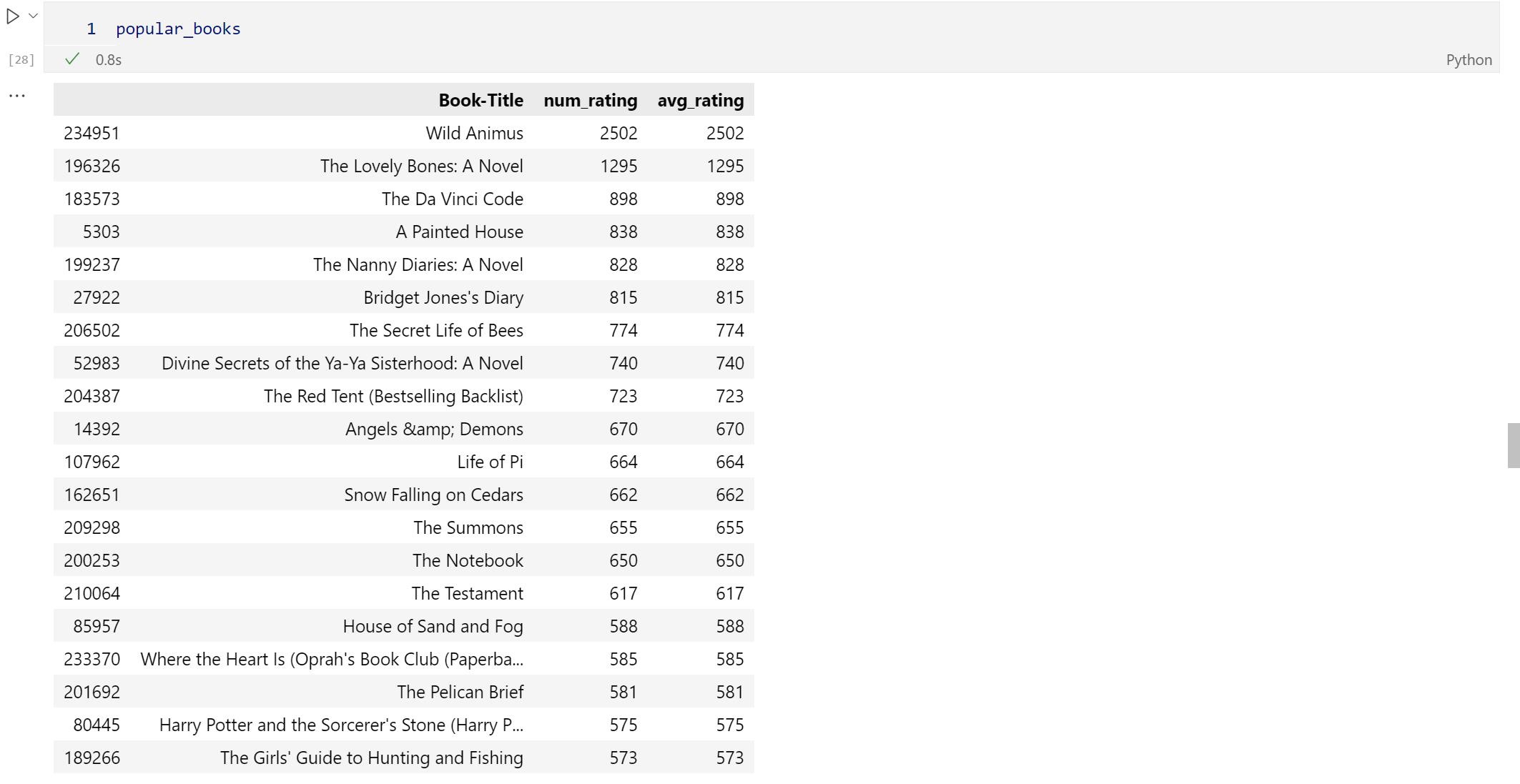
Extraction Of Users And Ratings of 200.
In this snippet, the popular_books dataset are being merged on 'books' Column of the books dataset and duplicates are being removed if any.
Further, the books are extracted which was rated has 200 ratings and checking what number of readers qualifying the criteria and that would be our actual readers that we could rely on.
Extraction Of Books Which Has More Than 50 ratings.
Now, likewise as previous code, same logic would apply here and filtered the books who got atleast 50 ratings and saved under the variable 'real_rating'.
Further, it was convered to Pivot table whose columns were UserID, Index were Book-Title and Values were given by Ratings.
As it was observed that, the pivot table has NaN values which was replaced by 0 using .fillna().
Now, using the Scipy, we create the Matrix which describe the individual users book preferences. Then, we apply the KNN model to impute the process with the help of its brute algorithm to provide result in the form of sparse matrix.
According to KNN alogrithm, the similarity of an input element depends on the eucladian distance from each clusters in the dataset. if there are two clusters named A and B. Then, X would fall into cluster A if datapoints of A is closer to X. In this case X would be the input provided by user.
so, now for determining the suggestions and distances. we fit the KNN model to the pivot which outputs the suggestion when we iterate through the suggestions.
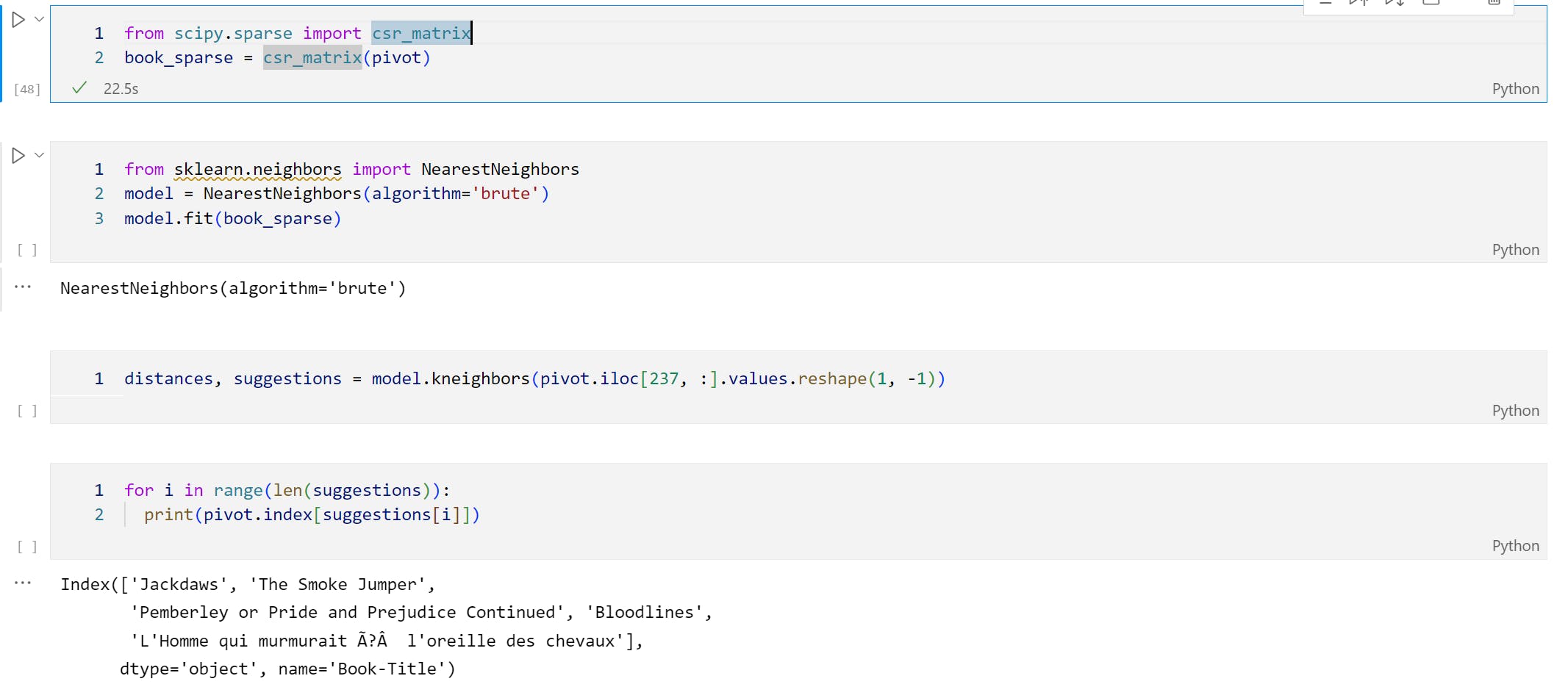
Now, in order to find the similar books, we use np.where() which brings the location of the same in the dataset. Now, first [0] indicates column having the eucladian distance and second [0] bring the column having title of the book. Here, I choose 'Animal Farm' book to set as input.


The above function 'recommend_book' was just implementation of the above steps if looks closely. so, lets test our function.

So, the function was working accurately and recommended 5 books as expected.
Conclusion
In conclusion, recommender system used by the tech giants like Amazon, Flipkart, Apple etc. are hybrid based and highly customized as per company requirements and goals. The system provides not just a list of books that the user might like to read but also plots the recommendation based on how the user has interacted with the system.